

{kind=link}
 The first challenge
The first challengeGCHQ (the UK's SIGINT agency) run an annual code-cracking competition... Well, that is to say they ran it this year and the year before. So that's annual right? This year's competition is (or was?) here: https://canyoufindit.co.uk, last year's was canyoucrackit.co.uk but that seems to be dead now.
The aim of this competition is I guess for them to get some publicity, in the hope that the people who complete their challenge might be eligible for employment in their super-secret Government lair. Whatever the motive, I gave it a bash this year and it was an entertaining way to fill a Saturday.
The competition features 5 challenges, which are more or less completely undescribed - you are presented with some kind of clue in the form of some data, and you must determine an "answer" from it. The entirety of the first challenge is shown in the image above.
What follows is a description of the challenges, some of the (often wrong) approaches I tried, and the eventual solutions, in the hope that someone somewhere might find them interesting and/or useful. For each challenge I've also included some code or a script of some sort which shows the method to find the solution. Those are all under "Files" in the sidebar.
The image above is the only clue you are presented with on visiting the website, and from this you must get 5 answers to enter into a series of boxes.
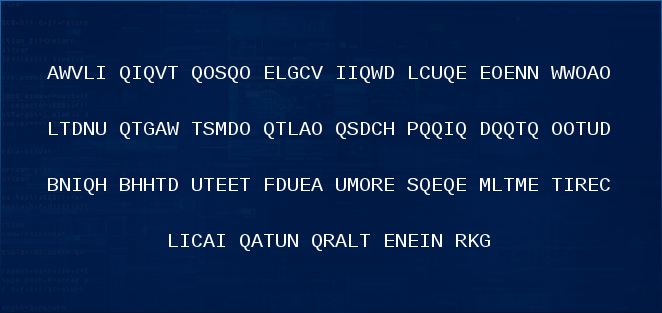
Here's the clue as a big long string:
It doesn't look like much, but the first thing you'll probably notice is that there's an awful lot of Qs. Perchance an homage to the head of the Secret Service's Q Branch? Proabably not.
Frequency Analysis(top)With a ciphertext like this where the whole thing is English letters, a simple look at the frequency of occurrence of letters can often tell you a lot because the English language is quite predictable. For instance, the letter 'e' is normally the most frequently used.
For this, (and for many many other things) I cracked out my trusty Python interpreter. In hindsight I really wish I hadn't, because it sent me on a massive wild goose chase, but more on that later.
>>> c = "AWVLIQIQVTQOSQOELGCVIIQWDLCUQEEOENNWWOAOLTDNUQTGAWTSMDOQTLAOQSDCHPQQIQDQQTQOOTUDBNIQHBHHTDUTEETFDUEAUMORESQEQEMLTMETIRECLICAIQATUNQRALTENEINRKG" >>> occurrences = {} >>> for l in c: ... try: ... occurrences[l] = occurrences[l] + 1 ... except KeyError: ... occurrences[l] = 1 ... >>> occurrences {'A': 8, 'C': 5, 'B': 2, 'E': 14, 'D': 8, 'G': 3, 'F': 1, 'I': 10, 'H': 4, 'K': 1, 'M': 4, 'L': 8, 'O': 10, 'N': 7, 'Q': 20, 'P': 1, 'S': 4, 'R': 4, 'U': 7, 'T': 14, 'W': 5, 'V': 3}
This shows us that 'Q' is by far the most frequent letter - something which my eyes noticed as soon as it saw the code. First I tried a Ceasar Cipher with the shift set to move 'Q' to 'E':
This is clearly nonsense, and is where I started to go a little off the rails. I continued to try hundreds of different shifts, as well as simple XOR, AND and OR operations, in combination with a Caesar Cipher, because I was so sure that's what it was (for no good reason).
Character Encoding(top)After hitting a brick wall with the Caesar Cipher I started looking at the letters to see what they made in binary. I had read the solutions to the previous year's challenge, and in that case the first clue was hexadecimal code, so I thought I'd give it a shot. It seemed unlikely that any kind of binary data would generate a nice neat string of all upper-case alpha characters, but what the hell.
The linux hexdump utility can do this, giving the output:
00000000 41 57 56 4c 49 51 49 51 56 54 51 4f 53 51 4f 45 |AWVLIQIQVTQOSQOE|
00000010 4c 47 43 56 49 49 51 57 44 4c 43 55 51 45 45 4f |LGCVIIQWDLCUQEEO|
00000020 45 4e 4e 57 57 4f 41 4f 4c 54 44 4e 55 51 54 47 |ENNWWOAOLTDNUQTG|
00000030 41 57 54 53 4d 44 4f 51 54 4c 41 4f 51 53 44 43 |AWTSMDOQTLAOQSDC|
00000040 48 50 51 51 49 51 44 51 51 54 51 4f 4f 54 55 44 |HPQQIQDQQTQOOTUD|
00000050 42 4e 49 51 48 42 48 48 54 44 55 54 45 45 54 46 |BNIQHBHHTDUTEETF|
00000060 44 55 45 41 55 4d 4f 52 45 53 51 45 51 45 4d 4c |DUEAUMORESQEQEML|
00000070 54 4d 45 54 49 52 45 43 4c 49 43 41 49 51 41 54 |TMETIRECLICAIQAT|
00000080 55 4e 51 52 41 4c 54 45 4e 45 49 4e 52 4b 47 0a |UNQRALTENEINRKG.|
00000090
Again, I didn't recognise anything in particular.
By grouping some of the letters into 16-bit numbers, and interpreting those as Unicode, you get something vaguely Chinese looking, which Google has a pretty good bash at translating into something that almost makes sense... "thirty bites shaved" = "thirty bytes shaved?" I spent a good while on this one, even getting a Chinese-speaking friend to take a look (cheers Rafe!) to no avail.
The Solution(top)So you know how I said I really wish I hadn't used Python to start with? That's because I couldn't see the wood for the trees.
Another friend of mine (Matt) showed me this handy site: http://math.fau.edu/richman/histogram.htm, which gives a histogram of a hunk of text compared to the expected distribution of the English language. For the clue, we get:
143 characters.
aaaaaaa XXXXXX
b X
ccc XXX
dddd XXXXXX
eeeeeeeeeeeee XXXXXXXXXX
fff X
gg XX
hhhh XXX
iiiiiii XXXXXXX
X
llll XXXXXX
mmm XXX
nnnnnnnn XXXXX
ooooooo XXXXXXX
ppp X
XXXXXXXXXXXXXX
rrrrrrrr XXX
ssssss XXX
ttttttttt XXXXXXXXXX
uuu XXXXX
v XX
ww XXX
yy
This is far too close to English to be a coincidence, so the
ciphertext must just be English... with far too many Qs.
What else does English have a lot of? Ah yes, spaces. It seemed reasonable to assume that by replacing the Qs with spaces, we would be back at the original characters, though of course as it is, it still looks like nonsense.
Now that we know there's no actual transformation of the text, you can start to focus on how you present it - 143 is a kinda strange number. Its only factors other than itself and 1 are 13 and 11.
Whilst I was busy trying to lay the text out as a 12x12 grid with a null terminating character, Matt layed it out as 13x11:
AWVLI I VT OS
OELGCVII WDL
CU EEOENNWWOA
OLTDNU TGAWTS
MDO TLAO SDCH
P I D T OOT
UDBNI HBHHTDU
TEETFDUEAUMOR
ES E EMLTMETI
RECLICAI ATUN
RALTENEINRKG
By reading the columns we get:So there's our first answer - the first section of the plain text alludes to the Turing test, giving the first answer: turing.
By visiting the web address at end - WWWDOTMETRODOTCODOTUKSLASHTURING we get to the start of Challenge 2
Huzzah! Success! I learnt a lot here:
- Don't dig too deep
- The answers are probably one word
- Each challenge probably reveals a web address for the next one
